MobileNet系列算法之V1
$MobileNet$系列是轻量级网络的一个系列,共有三个版本,本文介绍的$MobileNet$ $v1$,它提出了一种有效的网络架构和一组两个超参数,这些超参数允许模型构建者根据问题的约束条件为其应用选择合适尺寸的模型,以构建非常小的,低延迟的模型。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。
简介
其主要亮点有两个:
采用$Depthwise$ $Separable$ $Convolution$大大降低了计算量和参数量。
增加超参数α和ρ来控制网络模型。
如下图$1$所示为$MobileNet$ $v1$与$GoogleNet$和$VGG$ $16$在$ImageNet$上的对比结果,由图中可以看出,$MobileNet$ $V1$相比与$VGG$ $16$精度损失不超过一个点的情况下,参数量小了$32$倍之多!$MobileNet$ $v1$在速度和大小上的优势是显而易见的。

$Depthwise$ $Separable$ $Convolution$
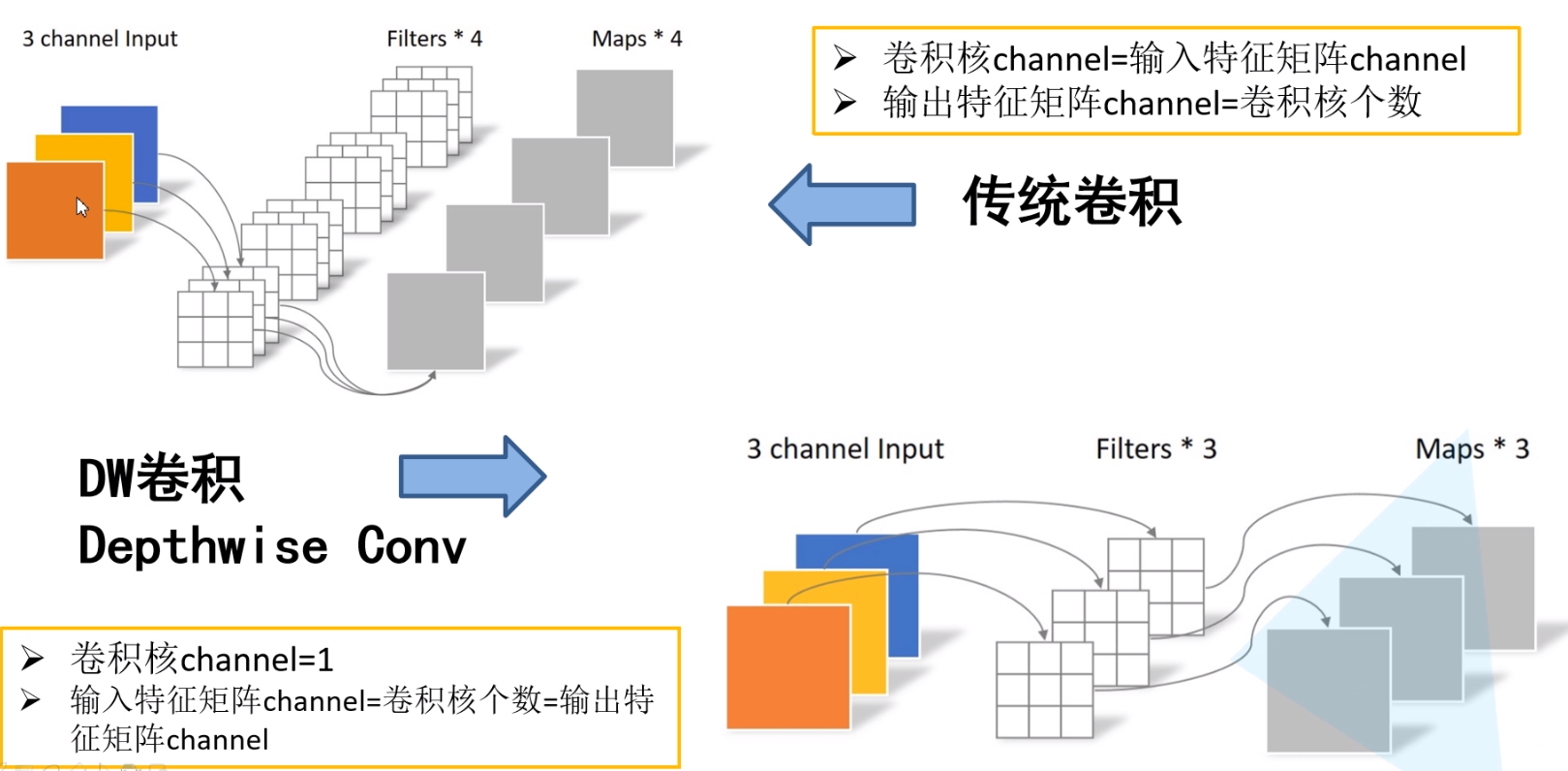
深度可分卷积是由$Depthwise$ $Convolution$(简称$DW$卷积)和$Pointwise Converlution$(简称$PW$卷积)组合而来,一般来说$DW$卷积用于提取特征,$PW$用于降低或者升高$channel$的维度。
$Depthwise$ $Convolution$
如下图$2$中左上角所示为传统卷积方式,即卷积核的$channel$是等于输入特征矩阵的$channel$,而输出特征矩阵的$channel$是等于卷积核的个数。
如下图$2$中右下角所示为$Depthwise$ $Converlution$。$Depthwise$ $Converlution$是将单个卷积核应用于每个输入通道,例如输入的特征为$RGB$三个通道,对应的$Depthwise$ $Converlution$就有三个卷积核分别去和$R$、$G$、$B$通道做计算,得到三个输出特征,更进一步看,$Depthwise$ $Converlution$的输出$channel$和输入$channel$是相等的。
$Pointwise$ $Convolution$
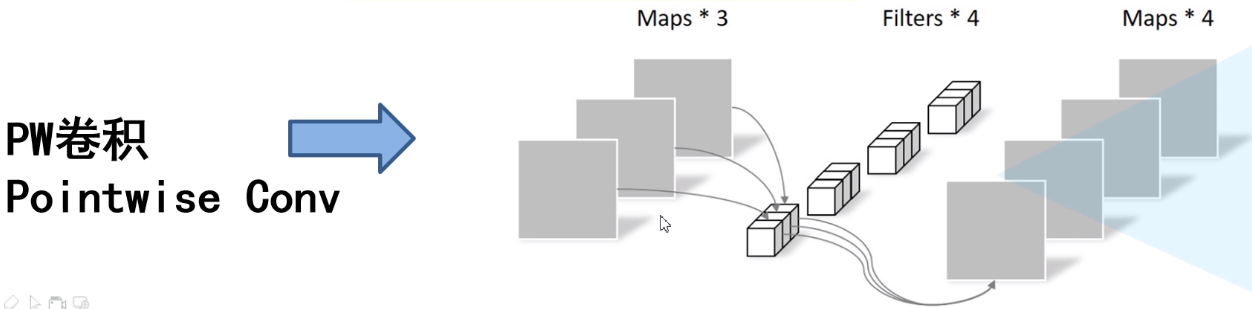
如下图$3$所示,其实$PW$卷积就是普通的卷积而已,只不过卷积核大小为1。通常$DW$卷积和$PW$卷积是放在一起使用的,先使用$DW$卷积提取特征,再使用$PW$卷积做通道维度的变换,二者合起来叫做$Depthwise$ $Separable$ $Convolution$(深度可分离卷积)。
那么问题来了,使用$Depthwise$ $Separable$ $Convolution$降低了多少计算量呢?
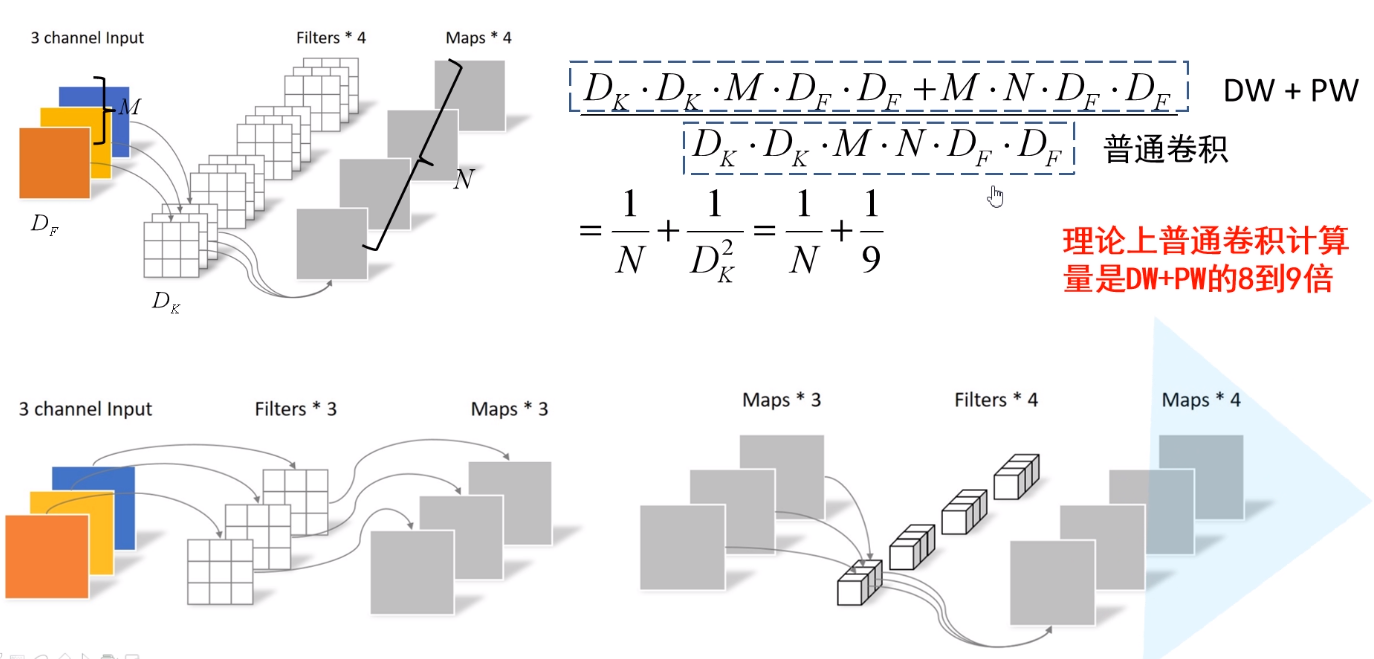
如上图$4$所示传统卷积和$Depthwise$ $Separable$ $Convolution$计算量对比。为其中${D_k}$是卷积核的大小、${D_F}$是输入矩阵的大小、$M$是深入矩阵的深度、$N$是输出矩阵的深度(卷积核的个数)。
正常的卷积核如上图4的上半部中尺寸为${D_k}$×${D_k}$×$M$×$N$。其计算量为${D_k}$·${D_k}$·$M$·$N$·${D_F}$·${D_F}$。
而深度可分离卷积中的卷积核的尺寸为${D_k}$×${D_k}$×$M$。这里$M$表示第$M$个卷积核(每个卷积核的通道数为$1$)用于第$M$个通道,其计算量为${D_k}$·${D_k}$·$M$·${D_F}$·${D_F}$。PW卷积核的尺寸为$1$x$1$x$M$x$N$,其计算量为$M$·$N$·${D_F}$·${D_F}$。因此深度可分离卷积的计算量为${D_k}$·${D_k}$·$M$·${D_F}$·${D_F}$+$M$·$N$·${D_F}$·${D_F}$。
深度分离卷积与标准卷积的计算量的比值为:
据此可知,$MobileNet$使用$3$x$3$深度可分离卷积能较少$8$-$9$倍的计算量,而精度只降低了一点点。具体如下图5所示:

超参数设计
在$Mobilenet$ $v1$原论文中,还提出了两个超参数,一个是$α$一个是$ρ$。
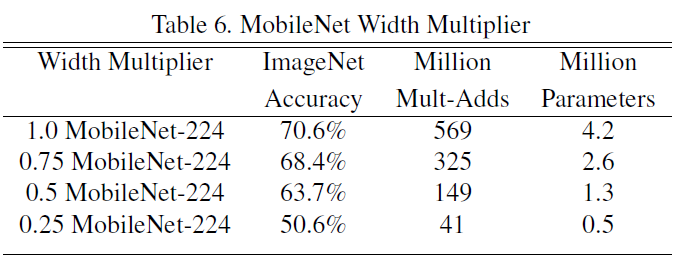
其中参数$α$,称为宽度因子。使用超参数$ɑ$对$DW$卷积核的个数以及$PW$卷积核的个数进行等比例缩小。因此其计算量变为:${D_K}$·${D_K}$·$ɑM$· $ɑ$$N$· ${D_F}$·${D_F}$这里的$ɑ$∈($0$,$1$], 这里的$ɑ$值分别取了$1$,$0.75$,$0.5$,$0.25$。当$ɑ$=$1$时即为上面的$MobileNet$结构。
如下图$6$是分别采用不同的$α$值对应的精确度、计算量和参数量,$α$值越小,对应的精度越低,但其计算量和参数量也会越少。用户可以根据不同的场景来选择不同的$α$参数。
第二个参数$ρ$,称为分辨率因子。超参数$ρ$用来降低空间分辨率。用法和$ɑ$一样。因此其计算量变为:${D_K}$·${D_K}$·$ɑ{D_F}$ ·$ρM$ · $ɑ{D_F}$·$ρ$${D_F}$。这里$ρ$∈($0$,$1$]。因此空间分辨率变为了$224$,$192$,$160$或$128$,能够降低计算量,但无法降低参数量。
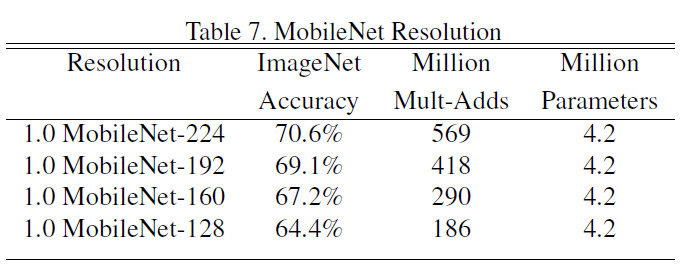
如下图7所示为分别采用不同的$ρ$值对应的精确度、计算量和参数量。随着$ρ$值降低,模型精度和计算量都在减少,但参数量并没有减少。
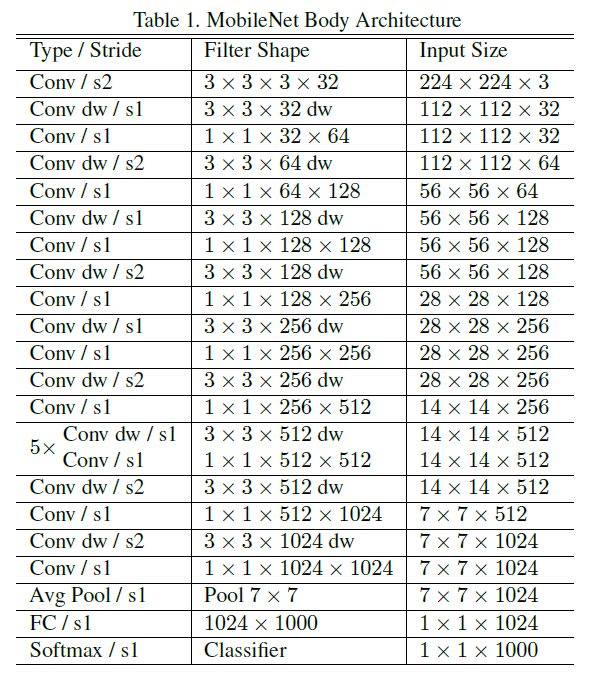
整体网络结构
如下图$8$为$MobileNet$ $V1$的整体结构图。
如下代码为$MobileNet$ $V1$的核心代码:
总结
$Mobilenet$ $v1$专注于移动端或嵌入式设备中的轻量级$CNN$网络,相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。
使用了$Depthwise$ $Separable$ $Convolution$,从而大大降低了计算量和参数量。
增加了两个超参数$α$和$β$,使得用户能够根据需求来控制网络模型大小。
引用
http://www.tensorinfinity.com/paper_185.html
https://arxiv.org/pdf/1704.04861.pdf
https://blog.csdn.net/qq_21997625/article/details/89513025
https://blog.csdn.net/weixin_44023658/article/details/105962635?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
https://blog.csdn.net/liuxiaoheng1992/article/details/103602929
https://mp.weixin.qq.com/s?src=11×tamp=1622358786&ver=3099&signature=tbckX3Ag4sZl23EHKVEwpMiWWZs5YCLJsEuMNnewpUqT1JPMMVHPeva8FzQuBGjT7bHg0X-he3eKs0AT22iwsQ58V02sQJpzm-aCxSMj54AYuKbEqAp*EASUAkCPLEGH&new=1
Last updated