$Xception$ 网络
大家好,小编又来啦。在前面的文章中呢我们介绍了关于 $Inception$ 的系列网络,在 $2017$ 年谷歌也是在 $Inception$-$V3$ 的基础上推出 $Xception$,在性能上超越了原有的 $Inception$-$V3$。下面我们带大家见识一下 $Xception$ 的庐山真面目吧!
简介
在 $Xception$ 中作者主要提出了以下一些亮点:
作者从 $Inception$-$V3$ 的假设出发,解耦通道相关性和空间相关性,进行简化网络,推导出深度可分离卷积。
提出了一个新的 $Xception$ 网络。
相信小伙伴们看到这里一定会发出惊呼,纳尼,深度可分离卷积不是在 $MobileNet$ 中提出的么?在这里需要注意的是,在 $Xception$ 中提出的深度可分离卷积和 $MobileNet$ 中是有差异的,具体我们会在下文中聊到咯。
$Xception$ 的进化之路
在前面我们说过 $Xception$ 是 $Google$ 继 $Inception$ 后提出的对 $Inception$-$v3$ 的另一种改进,作者认为跨通道相关性和空间相关性应充分解耦(独立互不相关),因此最好不要将它们共同映射处理,应分而治之。具体是怎么做呢?
1、先使用 $1×1$ 的卷积核,将特征图各个通道映射到一个新空间,学习通道间相关性。
2、再使用 $3×3$ 或 $5×5$ 卷积核,同时学习空间相关性和通道间相关性。
进化 $1$
在 $Inception$-$v3$ 中使用了如下图 $1$ 所示的多个这样的模块堆叠而成,能够用较小的参数学习到更丰富的信息。
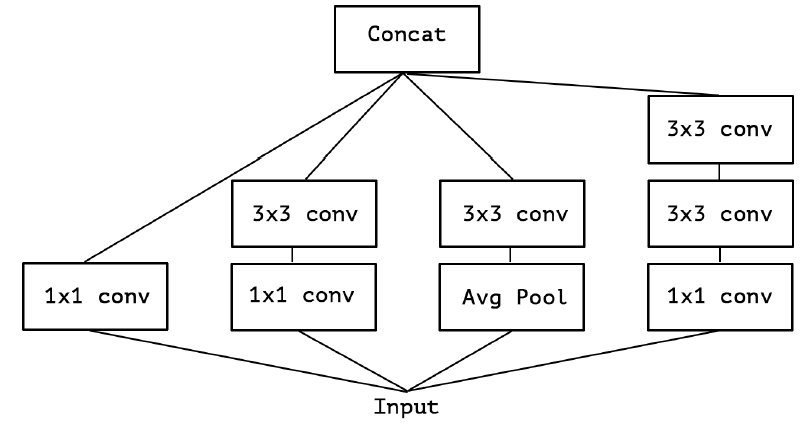
进化 $2$
在原论文中作者对于图 $1$ 中的模块进行了简化,去除 $Inception$-$v3$ 中的 $Avg$ $Pool$ 后,输入的下一步操作就都是 $1$ × $1$ 卷积,如下图 $2$ 所示:
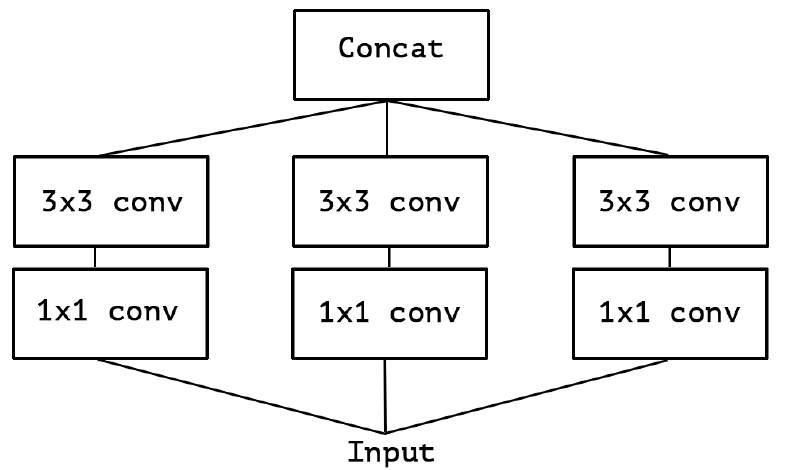
进化 $3$
更进一步,作者对于简化后的 $Inception$-$v3$ 模块中的所有 $1$ × $1$ 卷积进行合并,什么意思呢?就是将 $Inception$-$v3$ 模块重新构造为 $1$×$1$ 卷积,再进行空间卷积($3$×$3$ 是标准的那种多通道的卷积),相当于把 $1$×$1$ 卷积后的输出拼接起来为一个整体,然后进行分组卷积。如下图 $3$ 所示:

经过进化 $3$ 这种操作后,自然会有以下问题:分组数及大小会产生什么影响?是否有更一般的假设?空间关系映射和通道关系映射是否能够完全解耦呢?
进化 $4$
基于进化 $3$ 中提出的问题,作者提出了“$extreme$“版本的 $Inception$ 模块,如下图 $4$ 所示。从图 $4$ 中我们可以看出,所谓的“$extreme$“版本其实就是首先使用 $1$x$1$ 卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性,即对每个通道分别做 $3$×$3$ 卷积。
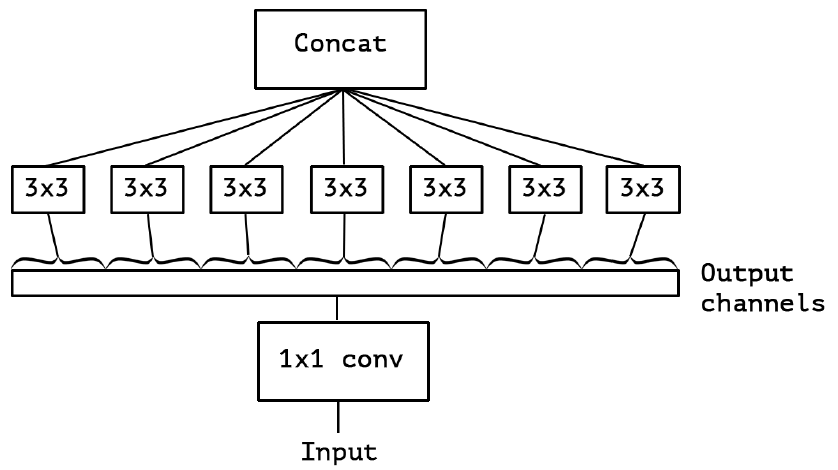
在此作者也说明了这种 $Inception$ 模块的“$extreme$“版本几乎与深度可分离卷积相同,但是依然是存在以下区别的:
1、通常实现的深度可分离卷积(如 $MobileNet$ 中)首先执行通道空间卷积($DW$ 卷积),然后执行 $1$×$1$ 卷积,而 $Xception$ 首先执行 $1$×$1$ 卷积。
2、第一次操作后是否加 $ReLU$,$Inception$ 中 $2$ 个操作后都加入 $ReLU$。其中“$extreme$“版本的 $Inception$ 模块为:$Conv$($1$×$1$)+$BN$+$ReLU$+$Depthconv$($3$×$3$)+$BN$+$ReLU$;而普通的深度可分离卷积结构为:$Depthconv$($3$×$3$)+$B$N+$Conv$($1$×$1$)+$BN$+$ReLU$。
而作者认为第一个区别不大,因为这些操作都是堆叠在一起的;但第二个影响很大,他发现在“$extreme$“版本的 $Inception$ 中 $1$×$1$ 与 $3$×$3$ 之间不用 $ReLU$ 收敛更快、准确率更高,这个作者是做了实验得到的结论,后面我们会介绍。
$Xception$ 网络结构
在提出了上面新的模块结构后,认识卷积神经网络的特征图中跨通道相关性和空间相关性的映射是可以完全解耦的。因为结构是由 $Inception$ 体系结构得到的“$extreme$“版本,所以将这种新的模块结构命名为 $Xception$,表示“$Extreme$ $Inception$”。并且作者还结合了 $ResNet$ 的残差思想,给出了如下图 $5$ 所示的基于 $Xception$ 的网络结构:
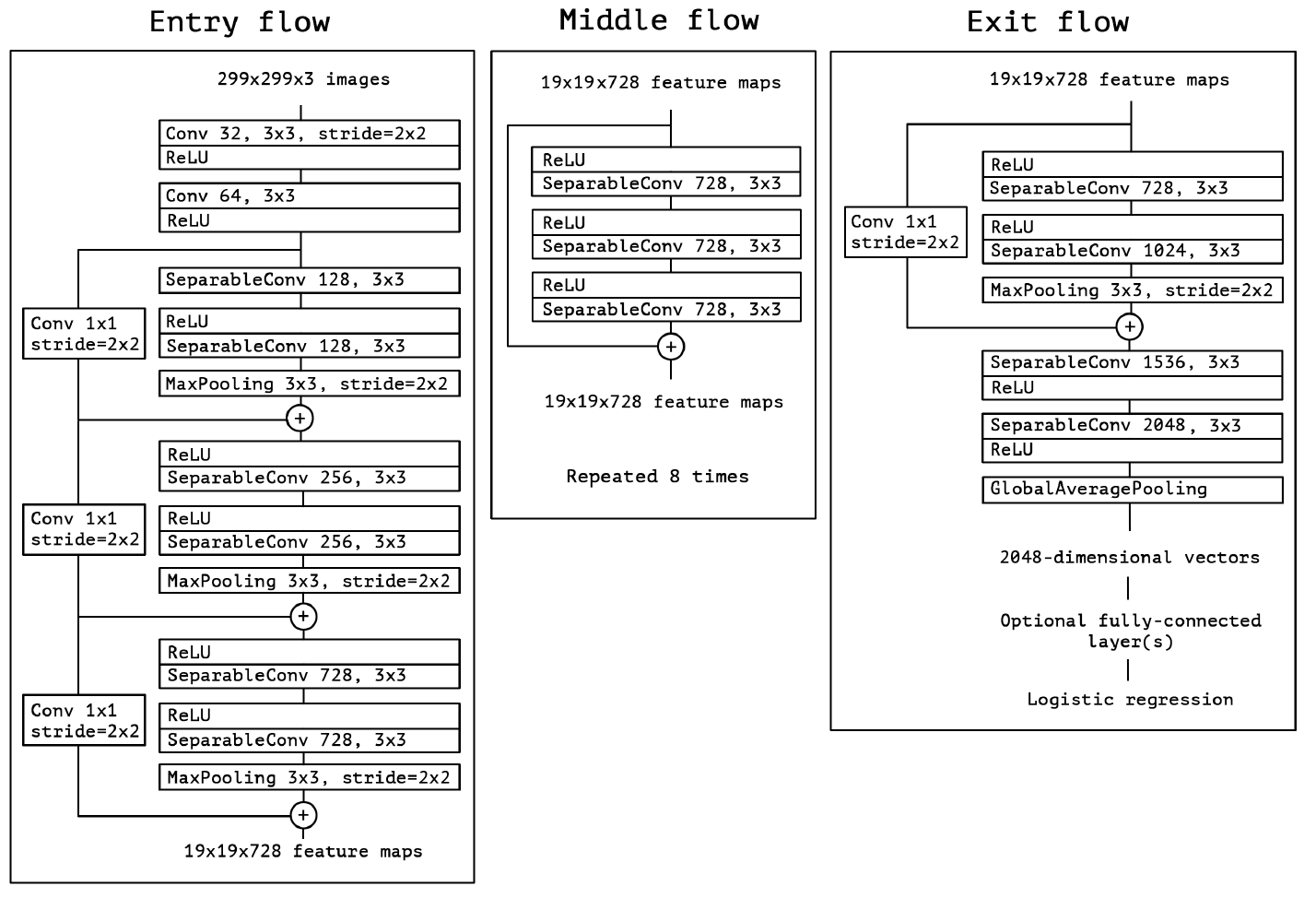
实验评估
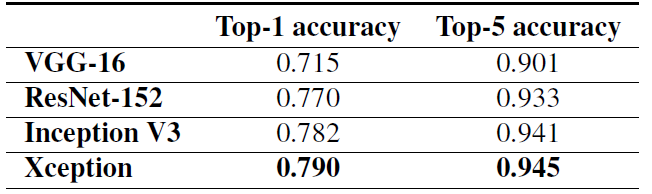
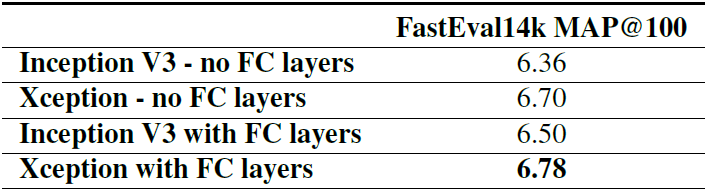
在训练验证阶段,作者使用了 $ImageNet$ 和 $JFT$ 这两个数据集做验证。精度和参数量对比如下图所示,从图中可以看到,在精度上 $Xception$ 在 $ImageNet$ 领先较小,但在 $JFT$ 上领先很多;在参数量和推理速度上,$Xception$ 参数量少于 $Inception$,但速度更快。

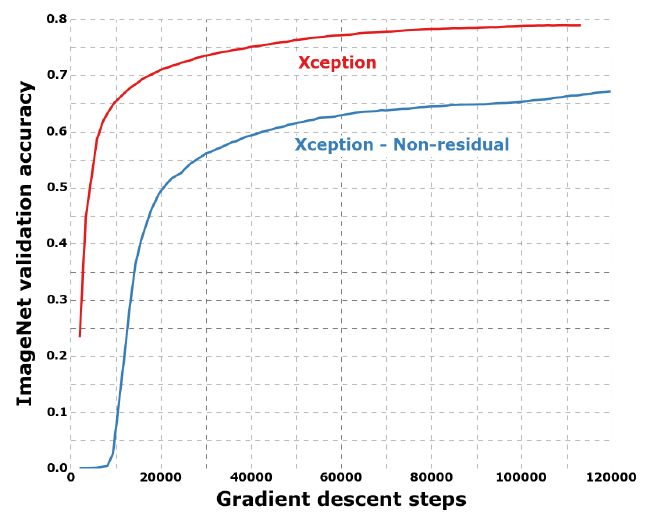
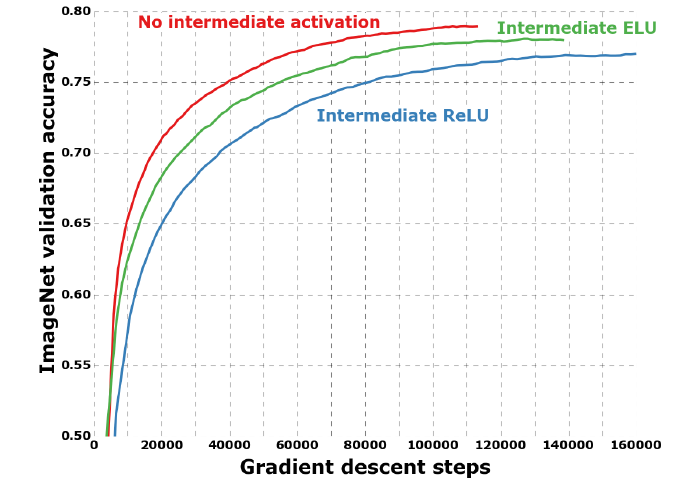
如下图所示,除此之外,作者还比较了是否使用 $Residual$ 残差结构、是否在 $Xception$ 模块中两个操作($1$×$1$ 卷积和 $3$×$3$ 卷积)之间加入 $ReLu$ 下的训练收敛速度和精度。从图中可以看出,在使用了 $Residual$ 残差结构和去掉 $Xception$ 模块中两个操作之间的 $ReLu$ 激活函数下训练收敛的速度更快,精度更高。
总结
在 $Xception$ 网络中作者解耦通道相关性和空间相关性,提出了“$extreme$“版本的 $Inception$ 模块,结合 $ResNet$ 的残差思想设计了新的 $Xception$ 网络结构,相比于之前的 $Inception$-$V3$ 获得更高的精度和使用了更少的参数量。
这里给出 $Keras$ 代码实现:
引用
https://arxiv.org/abs/1610.02357
https://zhuanlan.zhihu.com/p/127042277
https://blog.csdn.net/u014380165/article/details/75142710
https://blog.csdn.net/lk3030/article/details/84847879
https://blog.csdn.net/qq_38807688/article/details/84590459
Last updated