$MobileNet$ $v3$ 同样是由谷歌于 $2019$ 年提出的。在 $v2$ 网络的基础上,$v3$ 主要有以下四个亮点,其中第一点的 $NAS$ 在本文不做讨论:
在 $v2$ 的 $block$ 基础上引入 $Squeeze$ $and$ $Excitation$ 结构
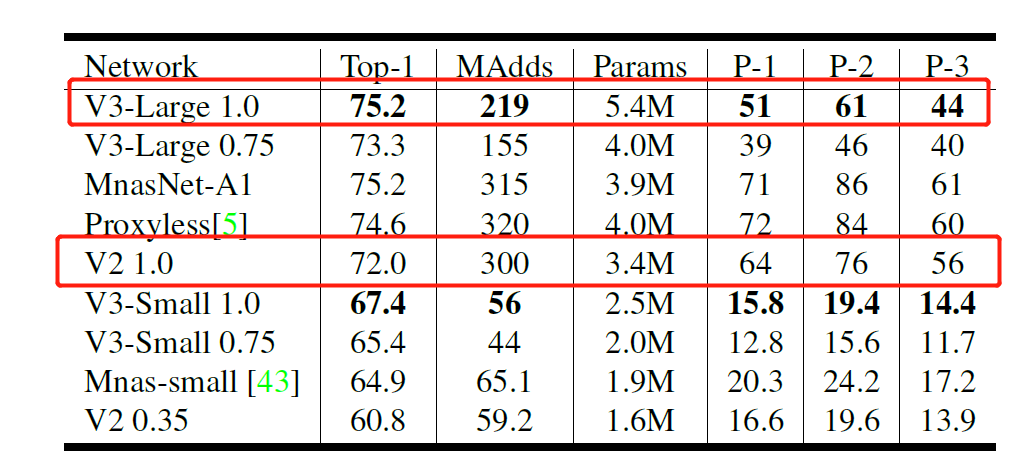
如下图 $1$ 所示为 $MobileNet$-$V3$ 和其他网络的一些性能对比。从图可知, $MobileNet$-$V3$ 相比于 $MobileNet$-$V2$ 性能提升了 $3.2$ 个点,在 $P-1$ 手机端单图推理性能达到 $51ms$。
图 $1$ $MobileNet$-$V3$ 和其他网络的一些性能对比 $Squeeze$ $and$ $Excitation$
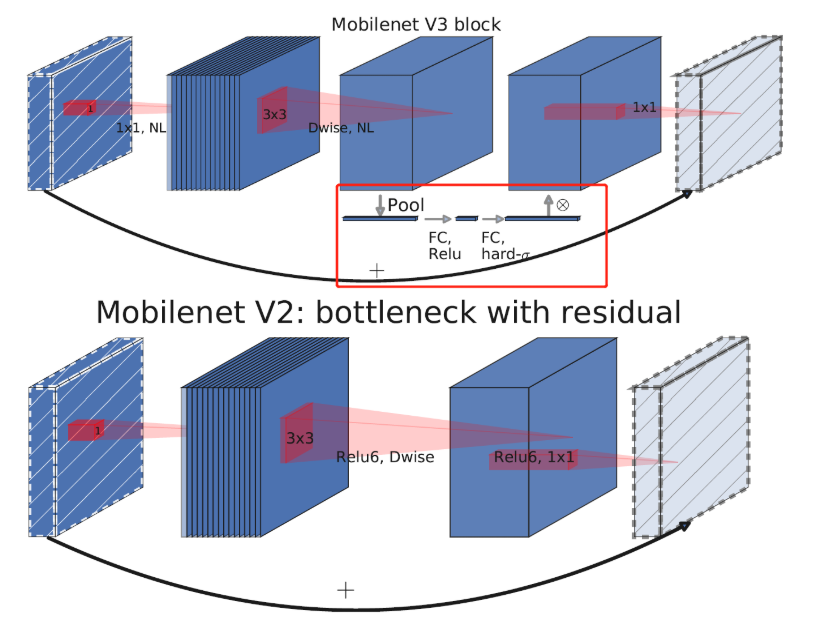
$Squeeze$ $and$ $Excitation$ 这一概念来源于 $SENet$,$SENet$ 是 $Momenta$ 公司发表于 $2017CVPR$,赢得了 $ImageNet$ 最后一届的图像识别冠军。其主要包括 $Squeeze$(压缩)和 $Excitation$(激活)两个部分。简单来说就是在 $MobileNet$-$V2$ 的倒残差结构中加入 $SE$ 模块,对 $3$×$3$ 卷积层后输出的特征矩阵采用两个全连接层来计算出特征矩阵每一个通道的“重要度”,然后给每个通道乘以相应的重要度得到一个全新的特征矩阵。如下如图 $2$ 中红色框所示。
图 $2$ $Squeeze$ $and$ $Excitation$ 模块 这里对于 $Squeeze$ $and$ $Excitation$ 的工作原理做一个简单的解释,详细的论文介绍之后会有文章和大家讨论。如下图所示输入一个 $2$×$2$×$2$ 的矩阵,采用平均池化后得到一个 $2$×$1$×$1$ 的矩阵,然后做两次全连接计算(第一次采用 $ReLU$ 激活函数,第二次采用 $H$-$sig$ 激活函数),得到输入 $2$×$2$×$2$ 的矩阵的两个通道的“重要度”,再将原 $2$×$2$×$2$ 输入矩阵每个通道中的数值都乘以对应通道的“重要度”,得到一个带有通道重要度的特征矩阵。 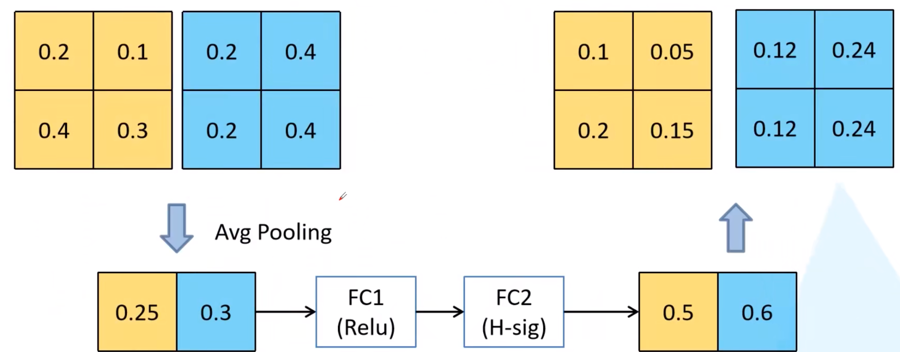
$h$-$swish$ 激活函数
$h$-$swish$ 激活函数是基于 $swish$ 的改进,$swish$ 最早是在谷歌大脑 $2017$ 的论文 $Searching$ $for$ $Activation$ $functions$ 所提出的,$swish$ 激活函数表达式如下:
swish(x)=x⋅sigmoid(βx) $swish$ 激活函数对一系列深度卷积网络的精度都有显著提升,$MobileNet$-$v3$ 也不例外,但是作者认为,作为一个轻量化的网络,$swish$ 激活虽然能带来精度提升,但由于 $swish$ 激活函数中的 $sigmoid$ 不容易求导的特性会使得网络在移动端设备上的推理速度受到一定的损失。所以在 $swish$ 激活函数的基础上,作者对其进行了改进,提出了 $h$-$swish$ 激活函数。表达式如下:
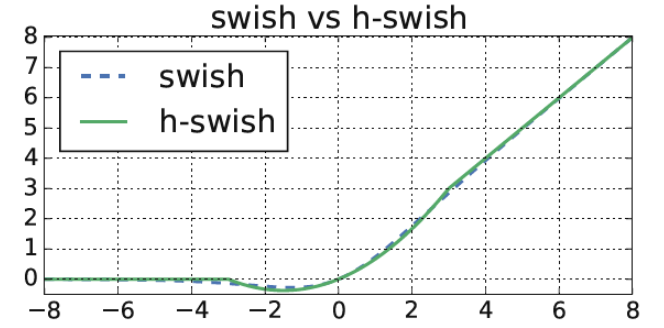
h−swish(x)=x⋅6ReLU6(x+3) $h$-$swish$ 的基本想法是用一个近似函数来逼近 $swish$ 函数,让 $swish$ 函数变得不那么光滑($hard$),基于 $MobileNet$-$v1$ 和 $v2$ 的经验,$v3$ 还是选择了使用 $ReLU6$ 来替换 $swish$ 中的 $sigmoid$。$swish$ 和 $h$-$swish$ 函数图像如下图 4 所示:
图 $4$ $swish$ 和 $h$-$swish$ 函数图像 1、作者经过实验证明第一层的 $bneck$ 使用 $16$ 个卷积核和使用 $32$ 个卷积核的精度是一样,而使用 $16$ 个卷积核自然是可以提升推理速度。如下图 $5$ 中所示,第一个 $bneck$ 的采用 $16$ 个卷积核。
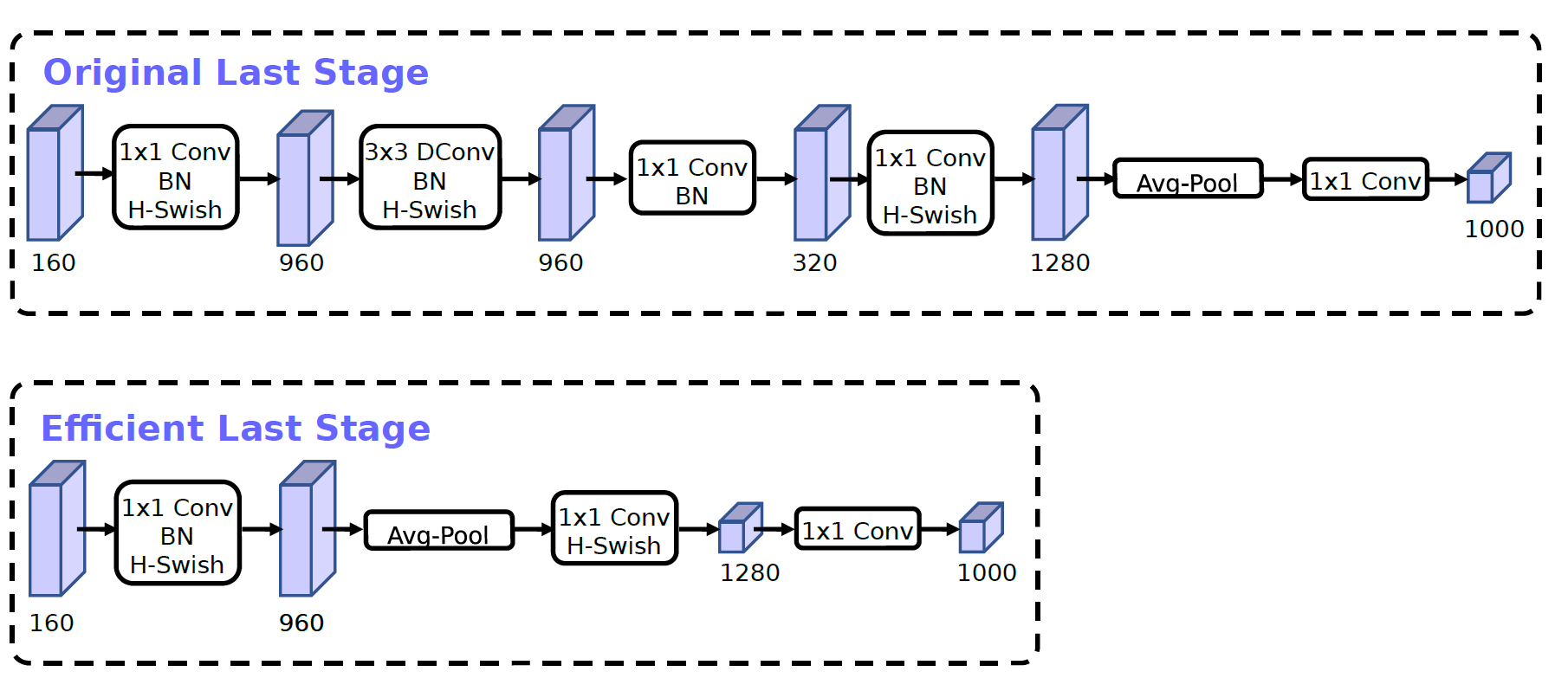
2、精简 $Last$ $Stage$:$MobileNet$ $v3$ 作者在使用 $NAS$ 搜索得到的网络最后的分类层叫 $Last$ $Stage$,如下图 $6$ 中上半部分所示,经过作者实验后采用下图下半部分的网络结构来精简 $Last$ $Stage$ 可以保证精度几乎不变的情况下,将单图推理性能提升 $11%$(减少约 $7ms$)。
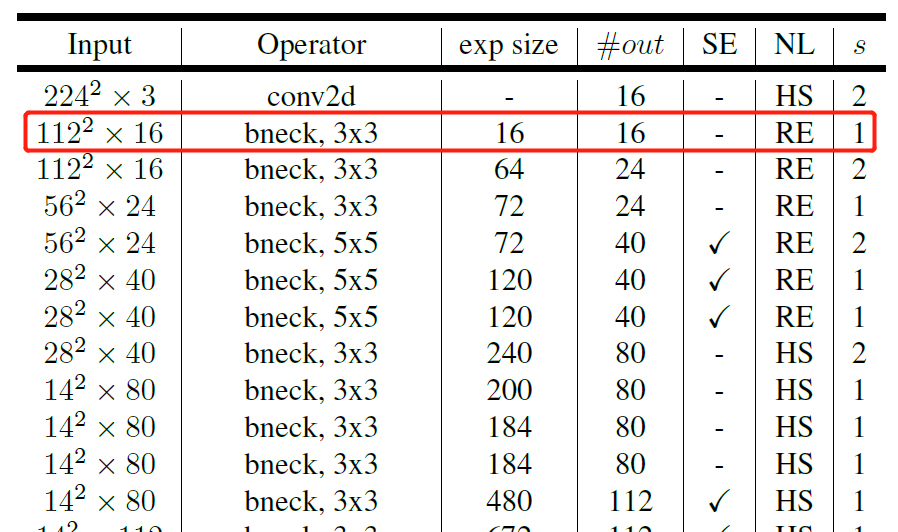
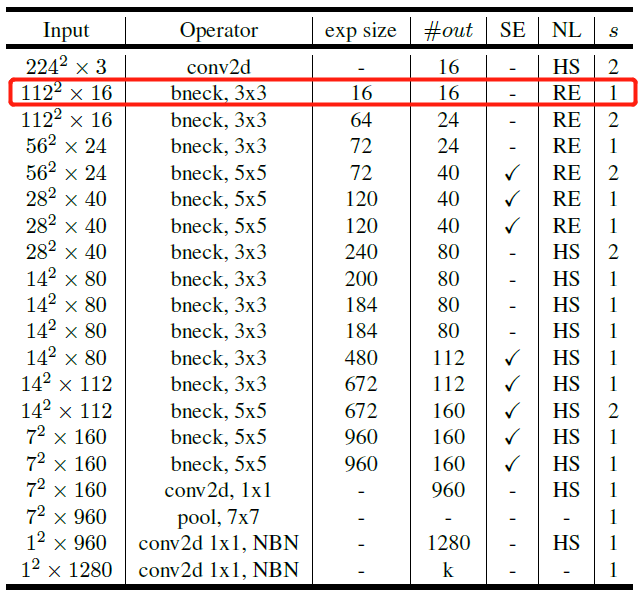
如下图 $7$ 所示为 $MobileNet$ $v3$ 的网络整体结构,其中的 $exp$ $size$ 表示的是在倒残差结构中第一层的 $1$×$1$ 升维卷积的通道数,$out$ 表示每一层 $bneck$ 的输出通道数,$SE$ 表示是否使用 $SE$ 模块,$NL$ 表示激活函数,$HS$ 表示使用 $h$-$sigmoid$ 激活函数,$RE$ 表示使用 $ReLU6$ 激活函数。需要注意的是,如下图中红色框中的第一个 $bneck$ 中的输入和输出通道数都是 16,因此在这个 $bneck$ 中是没有 $1$×$1$ 升维卷积层的。
图 $7$ $MobileNet$ $v3$ 网络整体结构 1、$MobileNet$-$V3$ 在 v2 的 block 基础上引入 Squeeze and Excitation 结构,增加了通道注意力机制。
2、对于 $NAS$ 搜索得到的网络结构重新设计了其耗时层结构,包括减少第一层的卷积核个数和精简 $Last$ $Stage$,在保证精度几乎不损失的前提下提升单图推理性能。
3、使用 $h$-$swish$ 激活函数加快网络收敛速度。
https://arxiv.org/pdf/1905.02244.pdf
https://www.bilibili.com/video/BV1GK4y1p7uE
https://www.tensorinfinity.com/paper_185.html
https://www.cnblogs.com/wxkang/p/14128415.html
https://blog.csdn.net/weixin_37737254/article/details/114325409?utm_medium=distribute.pc_relevant_t0.none-task-blog-2defaultBlogCommendFromMachineLearnPai2default-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2defaultBlogCommendFromMachineLearnPai2default-1.control
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/Test6_mobilenet