add_with_concat
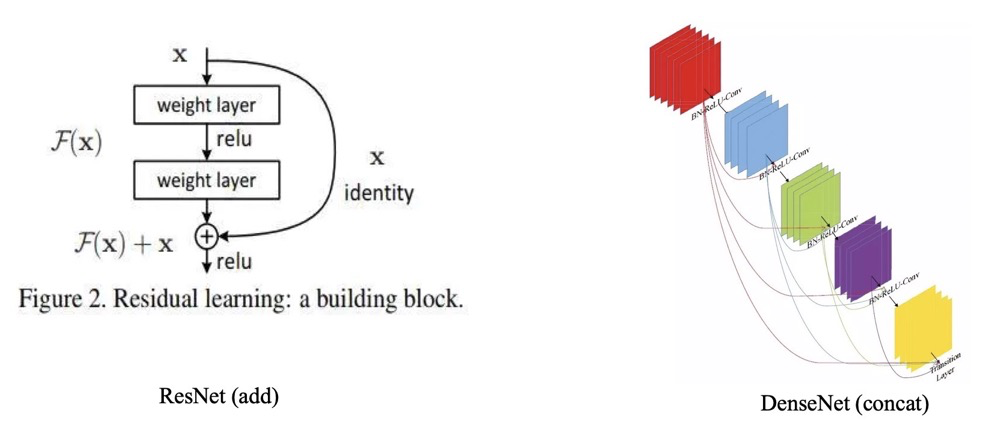
特征融合目前有两种常用的方式,一种是$add$操作,这种操作广泛运用于$ResNet$与$FPN$中。一种是$Concat$操作,这种操作最广泛的运用就是$UNet$,$DenseNet$等网络中。如下图所示: 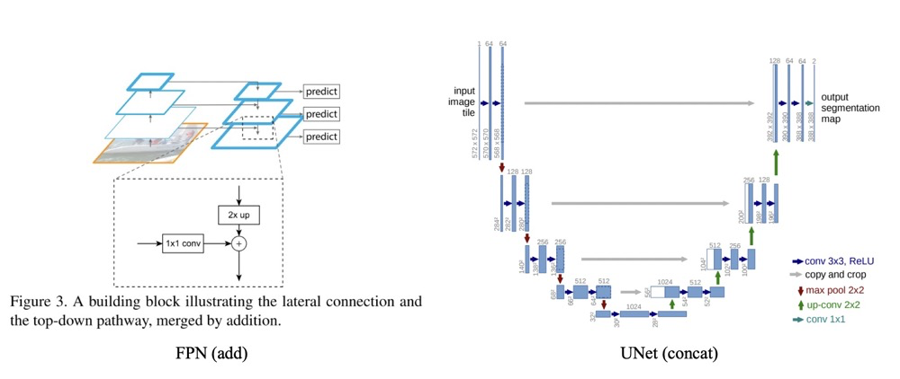
代码演示
联系
区别
结论
Last updated
特征融合目前有两种常用的方式,一种是$add$操作,这种操作广泛运用于$ResNet$与$FPN$中。一种是$Concat$操作,这种操作最广泛的运用就是$UNet$,$DenseNet$等网络中。如下图所示:
Last updated
>>> import torch
>>> img1 = torch.randn(2, 3, 58, 58)
>>> img2 = torch.randn(2, 3, 58, 58)
>>> img3 = img1 + img2
>>> img4 = torch.cat((img1, img2), dim=1)
>>> img3.size()
torch.Size([2, 3, 58, 58])
>>> img4.size()
torch.Size([2, 6, 58, 58])
>>>