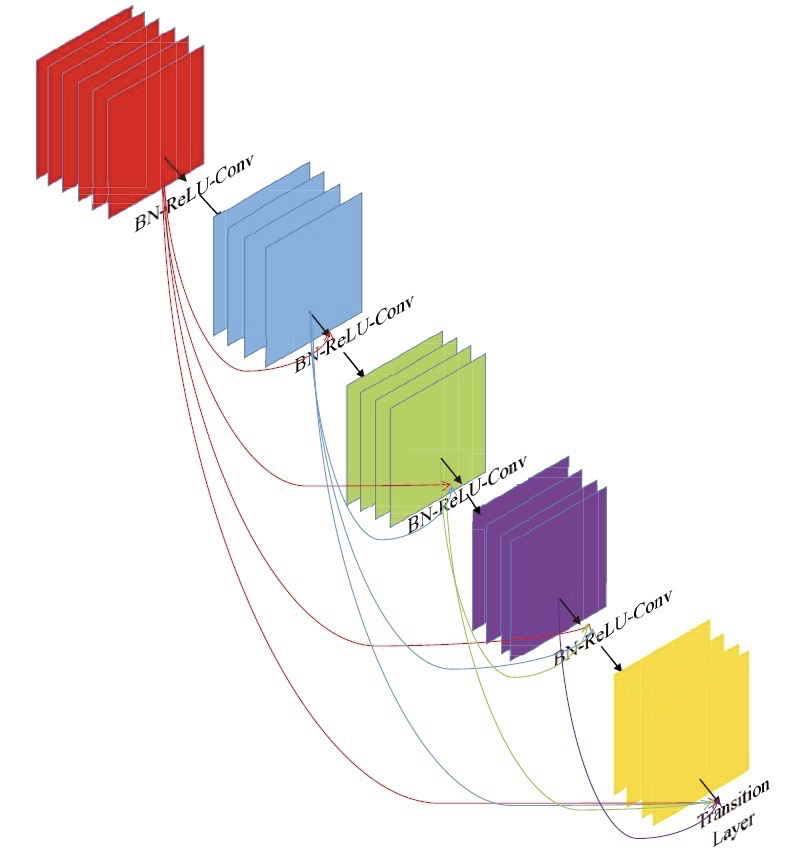
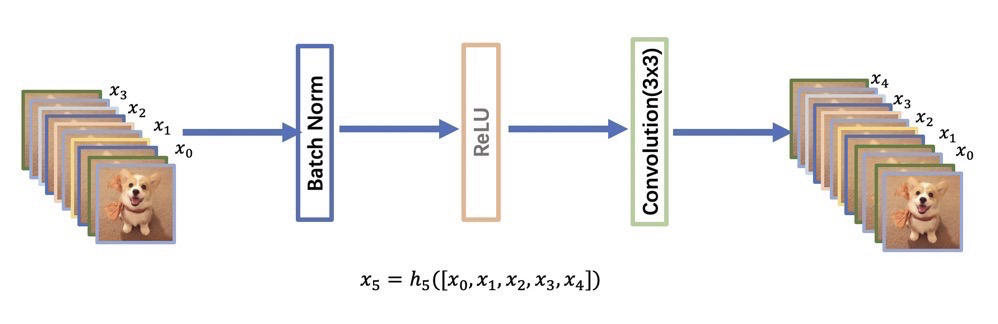
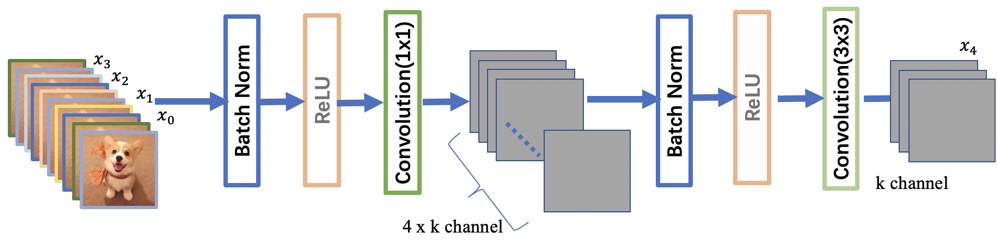
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
"""
:param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper
:param block_config: (list of 4 ints) number of layers in each DenseBlock
:param num_init_features: (int) number of filters in the first Conv2d
:param bn_size: (int) the factor using in the bottleneck layer
:param compression_rate: (float) the compression rate used in Transition Layer
:param drop_rate: (float) the drop rate after each DenseLayer
:param num_classes: (int) number of classes for classification
"""
super(DenseNet, self).__init__()
# first Conv2d
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
]))
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate)
# final bn+ReLU
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True))
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out