softmax及其相关变形
大家好,我是灿视。
最近在做一些分类问题,碰巧一个朋友在面试腾讯的时候,问到了一个问题:你了解到有哪些$Softmax$相关的变形?。
我也就把目前看到的资料给整理了下,希望给各位带来帮助!
$Softmax$在深度学习中,是一个常用的激活函数,广泛运用在图像分类任务中。那么,为什么会有这么多$Softmax$函数的变形呢?来,一步一步看吧~
首先,我们需要回顾下一开始的$Softmax$函数。
$1. Softmax$ $Loss$
在分类任务时,我们一般使用$Softmax$来接最后一层的输出,先对输出的特征做归一化操作,再将归一化之后的数值与标签做交叉熵损失函数来训练整个模型~
整个过程差不多是长这样的:
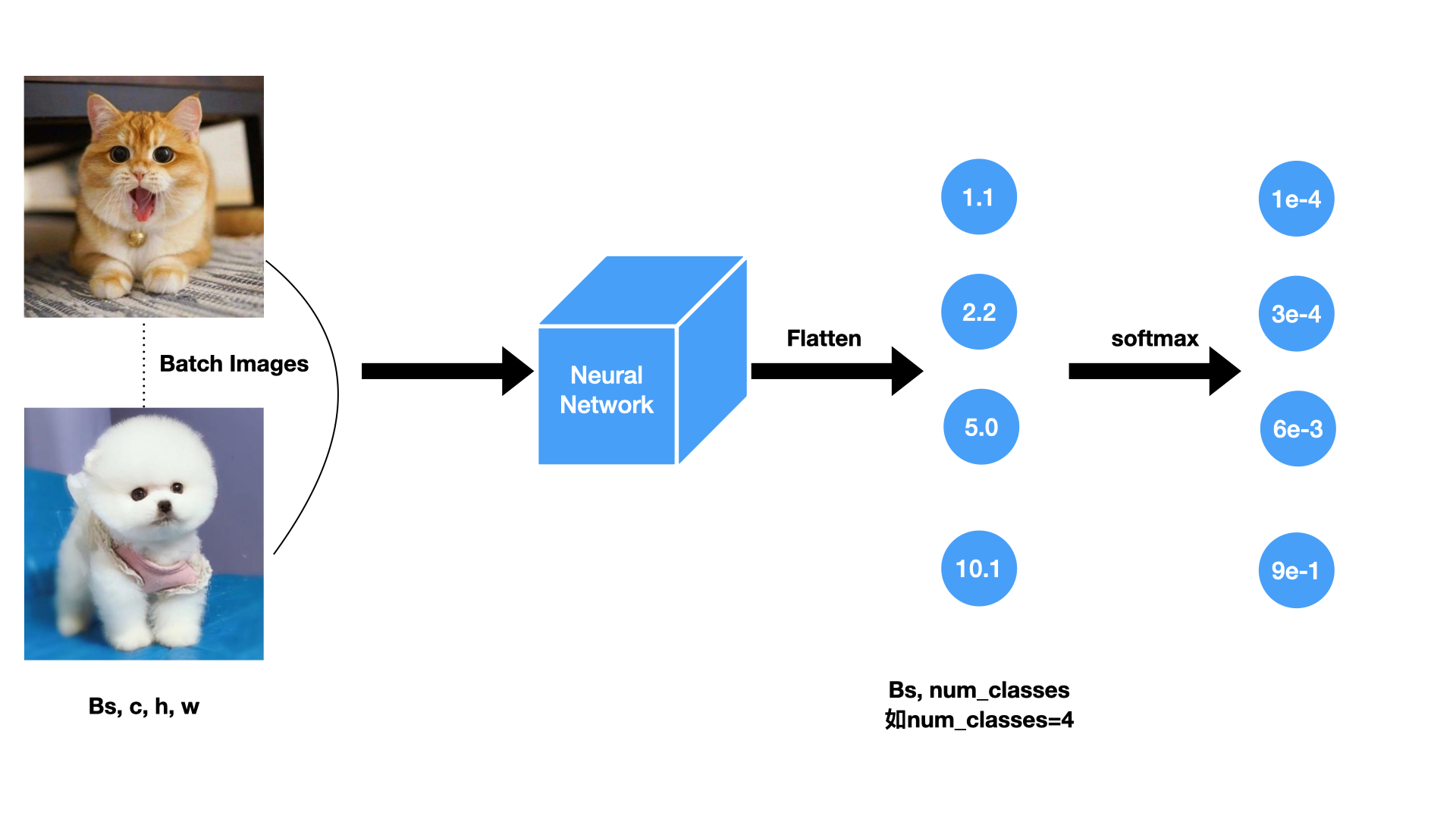
举个栗子:
如上图,我们输入了一个$batch$的图片,经过神经网络之后,经过全连接层或者GAP层,得到了一个$(Bs, num_classes)$的向量。再通过$Softmax$层来进行归一化。$Softmax$的计算公式:$S_{i}=\frac{e^{i}}{\sum_{j}e^{j}}$。
因此:
输出的值数值之和为1.
每个人的范围都是[0, 1]
如,给定一个向量[1.1, 2.2, 5.0,10.1],通过$Softmax$计算之后,得到的值为:[1.2260e-04, 3.6832e-04, 6.0568e-03, 9.9345e-01]。
当然,目前经常会考写个代码,我之前在面试的时候,就不止一次,被考到写$Softmax$。
参考代码:
然而,这种代码就存在一个数值不稳定的情况, 如:
根据公式,可以修改成:$S_{i}=\frac{e^{i-c}}{\sum_{j}e^{j-c}}$。代码因此修改成:
当然,$Softmax$还有反向传播的推导。推荐各位可以看下我之前整理的文章:,这里就不推导了。
$Softmax$可以直接与交叉熵损失函数结合在一起用,训练一个分类网络模型。它的特点就是优化类间的距离非常棒,但是优化类内距离时比较弱。
$ 2. soft$ $softmax$ $loss $
其公式修改成了:
这个公式主要是用在知识蒸馏中,知识蒸馏就是用一个大模型来先学习,再将学习到的知识,“转”给一个更小的模型。如下图所示:
 $T$就是一个调节参数,设置为$1$,那就是$Softmax$;$T$的数值越大则所有类的分布越'软'(平缓)。
$T$就是一个调节参数,设置为$1$,那就是$Softmax$;$T$的数值越大则所有类的分布越'软'(平缓)。
公式中,$T$参数是一个温度超参数,按照$softmax$的分布来看,随着$T$参数的增大,这个软目标的分布更加均匀。
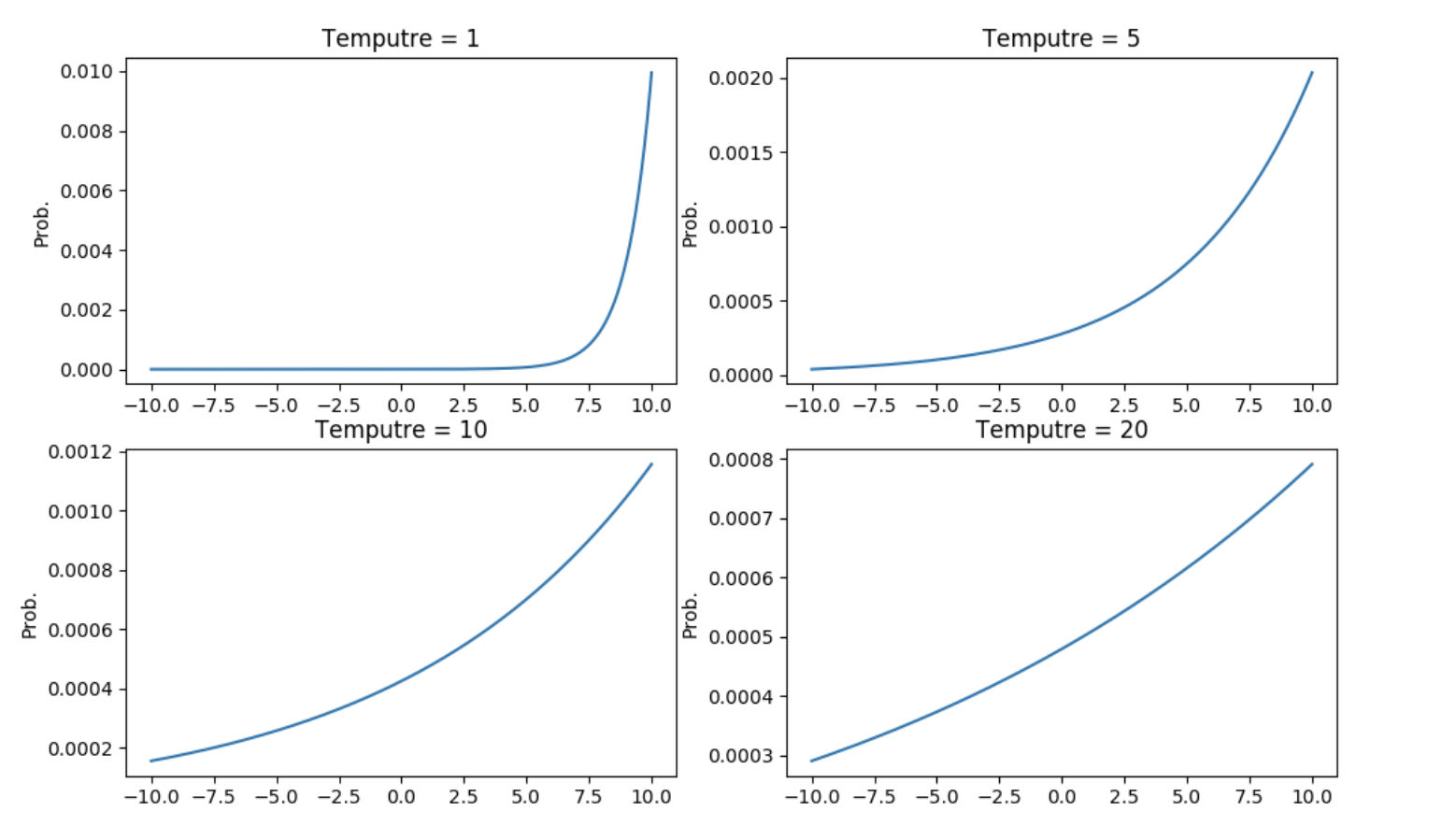
一个简单的知识蒸馏的形式是:用复杂模型得到的“软目标”为目标(在$softmax$中$T$较大),用“转化”训练集训练小模型。训练小模型时T不变仍然较大,训练完之后T改为$1$。
当正确的标签是所有的或部分的传输集时,这个方法可以通过训练被蒸馏的模型产生正确的标签。
一种方法是使用正确的标签来修改软目标,但是我们发现更好的方法是简单地使用两个不同目标函数的加权平均值。第一个目标函数是带有软目标的交叉熵,这种交叉熵是在蒸馏模型的$softmax$中使用相同的$T$计算的,用于从繁琐的模型中生成软目标。第二个目标函数是带有正确标签的交叉熵。这是在蒸馏模型的$softmax$中使用完全相同的逻辑,但在$T=1$下计算。我们发现,在第二个目标函数中,使用一个较低权重的条件,得到了最好的结果。由于软目标尺度所产生的梯度的大小为$\frac{1}{T^{2}}$,所以在使用硬的和软的目标时将它们乘以$T^{2}$是很重要的。这确保了在使用$T$时,硬和软目标的相对贡献基本保持不变。
T参数是什么?有什么作用?
$T$参数为了对应蒸馏的概念,在论文中叫的是$Temperature$。$T$越高对应的分布概率越平缓,如上图所示。
为什么要使得分布概率变平缓?网上的一些例子是:假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。 在这里$T$就是这个负重包,我们知道对于一个复杂网络来说往往能够得到很好的分类效果,错误的概率比正确的概率会小很多很多,但是对于一个小网络来说它是无法学成这个效果的。我们为了去帮助小网络进行学习,就在小网络的$softmax$加一个$T$参数,加上这个$T$参数以后错误分类再经过$softmax$以后输出会变大($softmax$中指数函数的单增特性,这里不做具体解释),同样的正确分类会变小。这就人为的加大了训练的难度,一旦将$T$重新设置为$1$,分类结果会非常的接近于大网络的分类效果。
soft target(“软目标”)是什么?
$soft$就是对应的带有$T$的目标,是要尽量的接近于大网络加入$T$后的分布概率。
hard target(“硬目标”)是什么?
$hard$就是正常网络训练的目标,是要尽量的完成正确的分类。
3. $Large$ $Margin$ $Softmax$ $Loss$
先来从分类效果可视化的角度上,直观了解下$Large$ $Margin$ $Softmax$ $Loss$干了啥。

如图,上面一行表示$training$ $set$,下面一行表示$testing$ $set$。每一行的第一个都是传统的$softmax$,后面$3$个是不同参数的$L-softmax$,看看类间和类内距离的差距!$softmax$ $loss$擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。而$large$-$margin$ $softmax$ $loss$则类内更加紧凑。接下来,我们分析下,这是为啥呢?
对于$Softmax$ $Loss$的公式如下:
其中,$f_{j}$表示$class$ $score$ $f$向量的第$j$个元素。$N$表示训练数据的数量。$log$函数的括号部分就是计算$Softmax$。其中$f_{y_{i}}$是全连接层的输出,可以写成:
这个式子就是$W$与$x$ 的内积,因此,可以写成下面:
因此,$L_{i}$变成下面的式子;
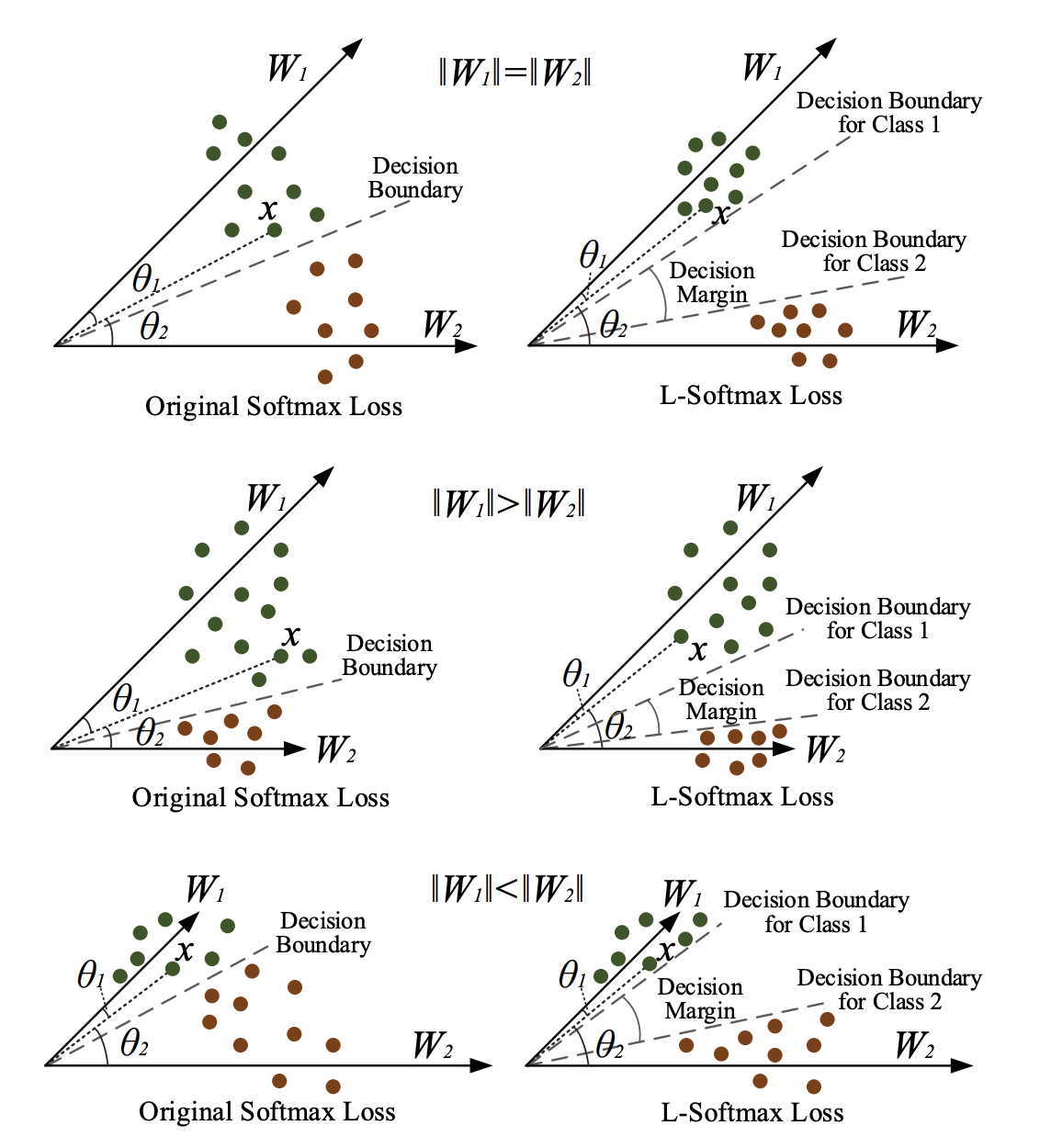
那么$Large$ $Margin$ $Softmax$ $Loss$是什么意思? 假设一个$2$分类问题,$x$属于类别$1$,那么原来的$softmax$肯定是希望$W_{1}^{T}x>W_{2}^{T}x$。也就是属于类别1的概率大于类别2的概率,等价于:
也就是将上面的不等式改成了:
因为$m$是正整数,$cos$函数在$0$到$π$范围又是单调递减的,所以$cos(mx)$要小于$cos(x)$。$m$值越大则学习的难度也越大,这也就是最开始那几个图代表不同$m$值的意思。因此通过这种方式定义损失会逼得模型学到类间距离更大的,类内距离更小的特征。
这样的话,$L-softmax$ $Loss$的$L_{i}$的式子就可以修改成:
其中:
$L-Softmax$ $loss$中,$m$是一个控制距离的变量,它越大训练会变得越困难,因为类内不可能无限紧凑。
我们也可以从下图的几何角度,直观地看两种损失的差别,$L-softmax$ $loss$学习到的参数可以将两类样本的类间距离加大。通过对比可以看到$L-softmax$ $loss$最后学到的特征之间的分离程度比原来的要明显得多。
这里,有一份参考代码:
4. $Center$ $Loss$
在说到$A-Softmax$ $Loss$之前,先要说一下$Center$ $Loss$。
$Center$ $Loss$听名字就很直观,需要寻找每一类的$Center$中心,来计算损失,最后可以达到类间距离越小越好。
先看下公式:
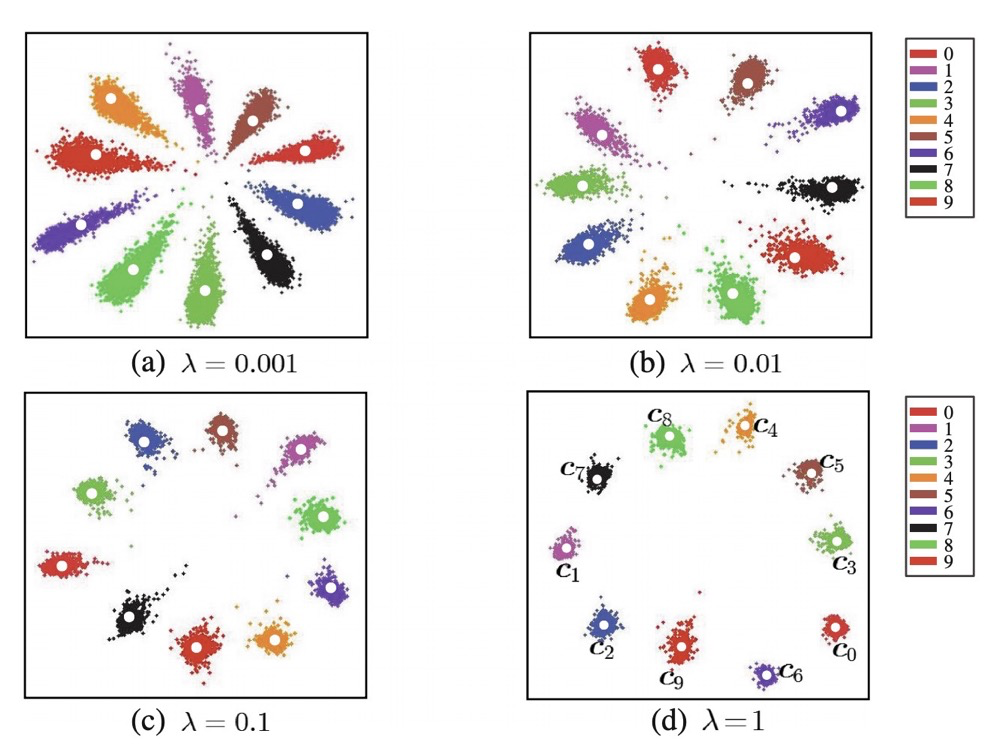
如果没有用$Center$ $Loss$,仅采用$Softmax$ $Loss$,则我们对分类结果可视化,可以看到:

当我们在$Softmax$ $Loss$上额外添加$Center$ $Loss$,再来看下可视化的结果:
这里给出一个$Center$ $Loss$的参考代码:
5. $A-Softmax$ $Loss$($SphereFace$)
$A-softmax$ $loss$ ($Angular$ $Softmax$ $Loss$)主要是因为$Original$ $Softmax$ $Loss$只能进行普通的多分类任务,其分类间距小,并且类内控制的效果一般,无法通过角度学习。而如$Center$ $Loss$可以很好地控制类内距离,但是控制类间距离能力不足,无法通过角度进行更加精细地学习,因此现在需要提出一种算法,可以满足两种功能:
类内距离越小越好
类间的距离越大越好
继续推导公式,在$Softmax$ $Loss$中,我们最后是接全连接层的输出,再接损失函数:
同样,全连接层的操作可以为:
则整个公式变形为:
这时候,原始的$Softmax$ $Loss$的特征分布结果为:

可以看到,其决策平面并不能很好的将其区分开。
这时候,引入了两个约束条件:
$||W||=1$
$b=0$
**为什么要引入这两个限制条件呢?**假设我们现在是一个二分类的任务,原先的决策边界为:$w_{1}x + b_{1}= w_{2}+b_{2}$,即$(w_{1}-w_{2})x+b_{1}-b_{2}=0$。当引入了上面的两个条件,这时候,决策边界就变成了$||x||(cos\theta_{1}-cos\theta_{2})=0$。此时分类的决策边界就取决于角度和当前样本了,就可以进行精细化分类了。
这时候,我们再对公式进行化简,从而得到:
可以看到化简的公式只有类别角度和样本,那么就可以使用角度对样本精细化分类了。如图:

要想通过角度分类,比如二分类,我们就需要通过判断$cos\theta_{1}>cos\theta_{2}$来判断样本是否属于$1$类,所以我们需要考虑如何使得$cos\theta_{1}$尽可能大于$cos\theta_{2}$,即使得类间距离足够大。
如何可以使得类内的距离足够小呢?
这时,引入$angular$ $margin$,用$m$表示。这样,又可以控制$\theta_{yi}$的取值范围,使得类内距离更小,即类内的样本更加紧凑。
当$cos(m\theta_{yi})$在$[0,\pi]$的取值范围内,其单调递减,并且存在上界,则此时的$\theta_{i}$的定义域为$[0, \frac{\pi}{\lambda}]$,值域为$[-1, 1]$,为了解决值域的限制,我们构造一个函数$\psi(\theta_{yi})$来代替$cos(m\theta_{yi})$。
则$Loss$修改成了:
为了方便实现 , $cos(m\theta)$ 又可以展开成如下形式:
因此,以二分类任务为例,我们可以概括行的看下上面的决策面:
$A-softmax$ $Loss$是$L-Softmax$ $Loss$的改进,归一化了权值$W$,使得训练可以集中在优化深度特征映射与特征向量角度上,降低了样本数量不均衡的问题。
看下论文中的可视化效果:
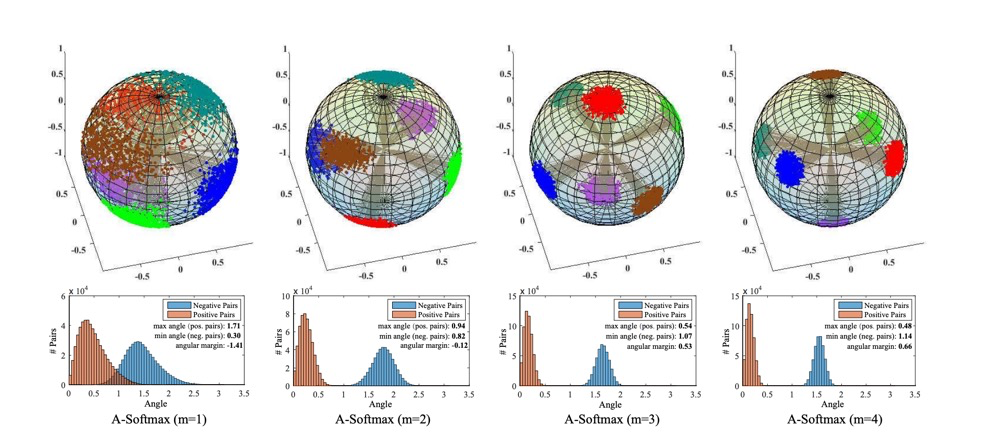
就是一个字,秀!!!可以返现,特征分得很好~
参考大佬的代码:
6. $NormFace$——了解$Softmax$ $Loss$的弊端
在优化人脸识别任务时,$Softmax$ $Loss$本身优化的是没有归一化的内积结果,但是最后在预测的时候,一般使用的是$Cosine$距离或者欧式距离,这就会导致优化目标与最终的距离度量并不一致。
在特征比较阶段,通常使用的都是特征的余弦距离:
而余弦距离等价于$L2$归一化后的内积,也等价$L2$归一化后的欧式距离(欧式距离表示超球面上的弦长,两个向量之间的夹角越大,弦长也越大)。
在$NormFace$中,形象可视化了$Softmax$ $Loss$学习到的特征是呈现辐射状。如,在$MNIST$中的实验可视化。
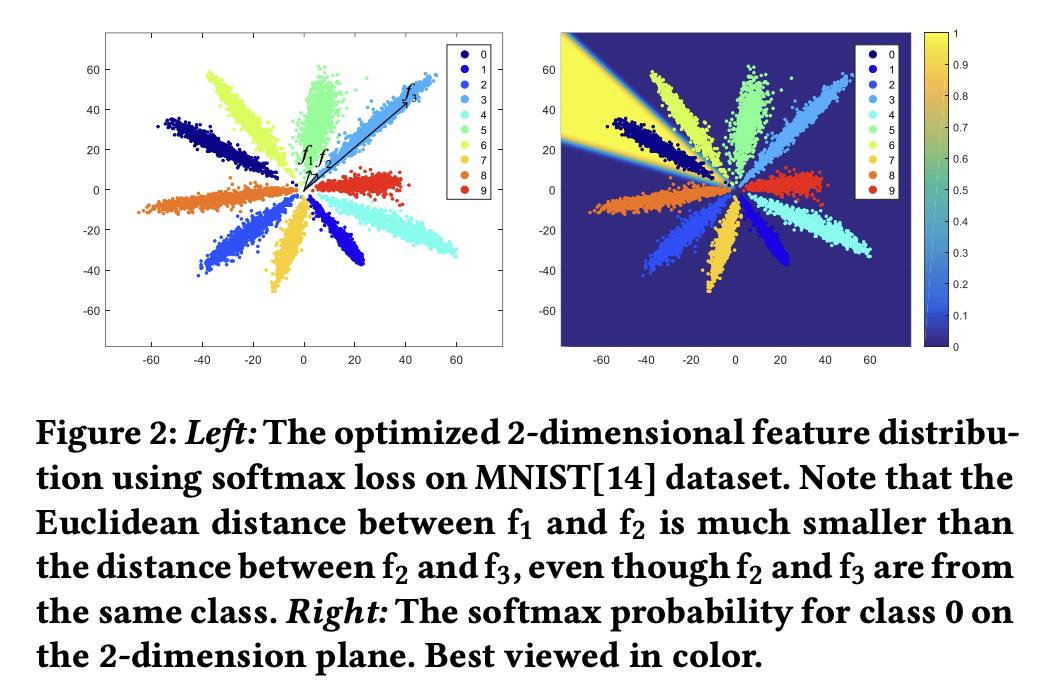
为什么会有特征呈现辐射状分布?
因为,使用$Softmax$之后的输出,每一类的概率为:
如$MNIST$分类,是一个十分类的任务,每一类会有一个权重向量$W_{0}, W_{1},...W_{9}$。因此,某一个特征$f$属于哪一类,取决于与哪一个权重向量的内积最大。
对于一个训练好的网络,权重文件是固定的,因此,$f$与$W$的内积,只取决于$f$与$W$的夹角。若$f$与$W_{0}$更近,则归为第一类,与$W_{9}$更近,则为第10类。在网络训练过程中,为了让每个分类更加明显,会让各个权值向量$W$逐渐分散开,相互之间有一定的角度,而靠近某一权值向量的特征就会被归为相应的类别,因此特征最终会呈辐射状分布。其特征的$Scale$越大,则其$Softmax$的$loss$就越小。
$NormFace$让模型直接基于特征之间的余弦距离进行学习,这就保持了训练与预测过程之间的一致性。
再来推一遍公式,普通的$Softmax$ $Loss$公式:
解释一下,这里的$m$是训练时的样本数,$n$是类别数,$y_{i}$为正确的标签,$W$与$b$分别表示矩阵的权重与偏置项,$f$是人脸的特征。
当我们在训练余弦距离的时候,我们需要对权重余特征进行规范化,同时也要舍弃偏置项。如下面的公式:
文章中,解释了$Softmax$前的$fc$有$bias$会造成引起分类的不准确。因为$softmax$之前的$fc$有$bias$的情况下会使得有些类别在角度上没有区分性但是通过$bias$可以区分,在这种情况下如果对$feature$做$normalize$,会使得中间的那个小类别的$feature$变成一个单位球形并与其他的$feature$重叠在一起,所以在$feature$ $normalize$的时候是不能加$bias$的。
到现在为止,$NormFace$解决了训练与测试不一致的问题。但是又出现了一个问题:模型难以收敛~
归一化之后的内积形式为:
该值的范围是$[-1, 1]$区间的数,当经过$Softmax$函数之后,即使每个类别都被完全分开了(即$f$和其标签对应类的权值向量$W_{f}$的内积为$1$,而与其他类的权值向量内积都是$-1$),其输出的概率也会是一个很小的数:$\frac{e^{1}}{e^{1} + (n-1)e^{-1}}$,在$n$=$10$时,结果为$0.45$;在$n=1000$时,结果为$ 0.007$,非常之小。而反向求导的时候,梯度$1-p$,会导致一直传回去很大的$loss$。
同时,论文中证明了此损失函数的下界为$log(1+(n-1)e^{-\frac{n}{n-1}\ell^{2}})$,其中$\ell$是$W$归一化之后的值。举例来说,训练CASIA-Webface数据集($n=10575$)时,损失值会从大约$9.27$下降到$8.50$,已经非常接近下界$8.27$了。这使得模型无法收敛。
证明过程:
如果把所有的$W$和特征的$L2norm$都归一化为$\ell$,且假设每个类的样本数量一样。则$Softmax$损失:
$L_s=-\frac{1}{m}\sum_{i-1}^{m}log\frac{e^{W^{T}{yi}f{i}+b_{yi}}}{\sum_{j=1}^{n}e^{W_{j}^{T}f_{i}+b_{j}}}$的下界为:$\log \left(1+(n-1) e^{-\frac{n}{n-1} \ell^{2}}\right)$
证:
因为每个类样本数量一致。假设有$n$个类别,则$L$可以等价于:
$L_{s}=-\frac{1}{n} \sum_{i=1}^{n} \log \frac{e^{W_{i}^{T} W_{i}}}{\sum_{j=1}^{n} e^{W_{i}^{T} W_{j}}}$
其中,$||W_{i}||=\ell$,因为其可以完全分开,所以$W_{i}$可以代表该类特征,这时同除可以得到:
$L_{s}=-\frac{1}{n}\sum_{i=1}^{n}log\frac{1}{1+\sum_{j=1,j \neq i}^{n}e^{W_{i}^{T}W_{j}-\ell^{2}}} =\frac{1}{n}\sum_{i=1}^{n}log(1+\sum_{j=1, j \neq i}e^{W_{i}^{T}W_{j}-\ell^{2}})$
因为,$exp$函数的凸性,则有:
$\frac{1}{n}\sum_{1}^{n}f(x_{i})>=f(\sum_{1}^{n}\frac{1}{n}x_{i})$,当且仅当$x_{i}$相等时,等号成立。
$\frac{1}{n}\sum_{i=1}^{n}e^{x_{i}} \geq e^{\frac{1}{n}\sum_{i=1}^{n}x_{i}}$
则:
$\mathcal{L}{\mathcal{S}} \geq \frac{1}{n} \sum{i=1}^{n} \log \left(1+(n-1) e^{\frac{1}{n-1} \sum_{j=1, j \neq i}^{n}\left(W_{i}^{T} W_{j}-\ell^{2}\right)}\right)$ 又$s(x)=\log \left(1+C e^{x}\right)$ 同是凸函数 有$ \frac{1}{n} \sum_{i=1}^{n} \log \left(1+C e^{x_{i}}\right) \geq \log \left(1+C e^{\frac{1}{n} \sum_{i=1}^{n} x_{i}}\right)$
所以
$\begin{aligned} \mathcal{L}{\mathcal{S}} & \geq \log \left(1+(n-1) e^{\frac{1}{n(n-1)} \sum{i=1}^{n} \sum_{j=1, j \neq i}^{n}\left(W_{i}^{T} W_{j}-\ell^{2}\right)}\right) \ &=\log \left(1+(n-1) e^{\left(\frac{1}{n(n-1)} \sum_{i=1}^{n} \sum_{j=1, j \neq i}^{n} W_{i}^{T} W_{j}\right)-\ell^{2}}\right) . \end{aligned}$
注意到
$\begin{array}{c} \sum_{i=1}^{n} ||W_{i} |{2}^{2}=n \ell^{2}+\sum{i=1}^{n} \sum_{j=1, j \neq i}^{n} w_{i}^{T} W_{j} \ \sum_{i=1}^{n} \sum_{j=1, j \neq i}^{n} W_{i}^{T} W_{j} \geq-n \ell^{2} \end{array}$
所以:
$L_{s} \geq log(1+(n-1)e^{-\frac{n\ell^2}{n(n-1)}-\ell^{2}})=log(1+(n-1)e^{-\frac{n}{n-1}\ell^{2}})$
考虑等号成立的条件需要任何$W_{a}$$W_{b}$内积相同,而对于$h$维向量$W$,只能找到$h+1$个点,使得两两连接的向量内积相同,如二维空间的三角形和三位空间的三面体,但是最终需要分类的数目可能远大于特征维度,所以经常无法取到下界。
最后,论文给出了一个解决方案,在$normalize$之后加上一个$Scale$层,让这个差距拉大,最终$normalize$之后的$Softmax$ $Loss$如下,其中$W$与$f$都是归一化的。同样加了尺度因子$s$,但这里推荐用自动学习的方法。
$L_{s} = -\frac{1}{m} \sum_{i=1}^{m} \log \frac{e^{s \tilde{W}{y{i}}^{T} \tilde{\mathbf{f}}{i}}}{\sum{j=1}^{n} e^{s \tilde{W}{j}^{T} \tilde{\mathbf{f}}{i}}}$
7. CosFace: Large Margin Cosine Loss
所有基于$softmax$ $loss$改进的损失都有相同的想法:最大化类间方差和最小化类内方差。 在这篇文中中,新提出了一个新的损失函数:$large$ $margin$ $cosine$ $loss$ ($LMCL$)。我们通过对特征向量和权重向量进行$L2$归一化以消除径向变化,将$softmax$ $loss$表示为$cosine$ $loss$。在此基础上,引入余弦间隔($margin$),进一步最大化角空间中的间距(角间距)。
来,继续推公式:
其中,$f_{j}$是当前的类别权重$W_{j}$和$feature$ $x$的乘积,$bias$继续设置为0。
$f_{j}=W_{j}^{T} x=\left|W_{j}\right||x| \cos \theta_{j}$
然后,分别对$W$与$X$做$L2$ $Normalization$,使得$Norm$为1,但是考虑到$X$得$Norm$的大小会导致训练$Loss$太大($Softmax$得值太小),进行一次缩放,固定为大小$S$,所以修改后的$Loss$如下:
该式也称为$NSL$ ($Normalized$ $version$ $of$ $Softmax$ $Loss$)。
到目前为止,都只是转换学习空间而已,由最开始的优化内积变成了现在的优化角度,但是学习到的特征都是表征信息,远没到达我们的目标:判别特征信息。
所以我们引入一个$cosine$ $margin$来进行度量的约束,让当前样本所属的类别在减去一个$m$之后仍然属于这个类别,即:
这时,损失函数变成了$LMCL$:
其中,$margin$的相减操作是针对$cosine$的,所以$scale$的缩放仍然放在最外层。
因此,关于决策边界,论文也给了一个图:如下:
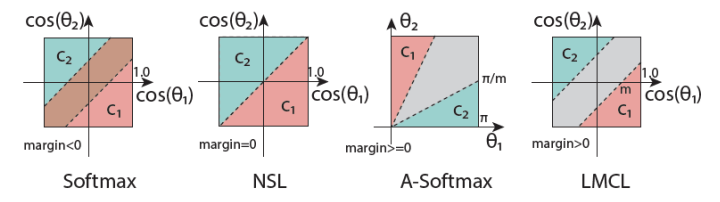
$softmax$ $Loss$
决策边界:$||W_{1}||cos(\theta_{1})=||W_{2}||cos(\theta_{2})$
如上图所示,可以看出决策边界由权值变量和角度的$cosine$值一起决定,这样子就导致了,在$cosine$维度进行度量的时候,两个类别之间会出现重叠($margin<0$)。
$NSL$ $Loss$
决策边界:$cos(\theta_{1})$=$cos(\theta_{2})$
而$NSL$ $loss$是指权值和特征都进行正则化。在$cosine$维度进行度量的时候,两个类别之间有一个明确的决策边界。但是,由于边界空间为$0(margin=0)$,导致处于边缘的情况,很容易出现分类错误。
$A-Softmax$ $Loss$
决策边界:$C_{1}: \cos \left(m \theta_{1}\right) \geq \cos \left(\theta_{2}\right)$, $C_{2}: \cos \left(m \theta_{2}\right) \geq \cos \left(\theta_{1}\right)$
$A-Softmax$是对角度$theta$进行约束,故呈现在$cos(\theta)$的坐标中,是一个扇形页面分界区。但是$A-Softmax$的$margin$是不连续的,随着$theta$的降低,$margin$也在跟着减小,当$theta$等于$0$的时候$margin$甚至消失,另外,$A-Softmax$还需要解决非单调性问题。
$LMCL$
决策边界:$C_{1}: \cos \left(\theta_{1}\right) \geq \cos \left(\theta_{2}\right)+m$,$C_{2}: \cos \left(\theta_{2}\right) \geq \cos \left(\theta_{1}\right)+m$
$LMCL$却克服了上述$loss$的缺点,两个类别之间有一个明确的边界空间$(margin>0)$,相对于前几种$loss$,有更好的鲁棒性。 注意,在$LMCL$中,作者证明了$s$的范围: $s \geq \frac{C-1}{C} \log \frac{(C-1) P_{W}}{1-P_{W}}$
参考代码如下:
8. $Additive$ $Margin$ $Softmax$ $(AM-Softmax$ $Loss$ $)$
之前的$L-Softmax$,$ A-Softmax$引入了角间距的概念,用于改进传统的$softmax$ $loss$函数,使得人脸等特征具有更大的类间距和更小的类内距。这里又有大佬提出一种更直观和更易解释的$additive$ $margin$ $Softmax$ $(AM-Softmax)$。同时,本文强调和讨论了特征正则化的重要性。
上文中也介绍到了$A-Softmax$ $Loss$,其表达式为:
$A-Softmax$ 与$L-Softmax$均引入了一个参数因子$m$,将权重W和f的$cos$距离变为$cos(mθ)$,通过$m$ 来调节特征间的距离。
在$AM-Softmax$中,是将$cos(\theta)$的式子改写成了:
上式是一个单调递减的函数,且比$L-Softmax$与$A-Softmax$所有的$\psi(\theta)$的形式与计算时更加简单。除了将$b$=0, $||W||=1$,作者进一步将 $||x||=1$,最终的$AM-Softmax$写为:
其中$s$为一个缩放因子,大佬设置为固定为$30$。
大佬也讨论了关于$AM-Softmax$的几何解释。相关的$m$控制着分类边界的大小,对于二分类任务,对于$1$类的分类边界,从$W^{T}{1}P{0}=W^{T}{2}P{0}$变成了$W^{T}{1}P{0}-m=W^{T}{2}P{0}$
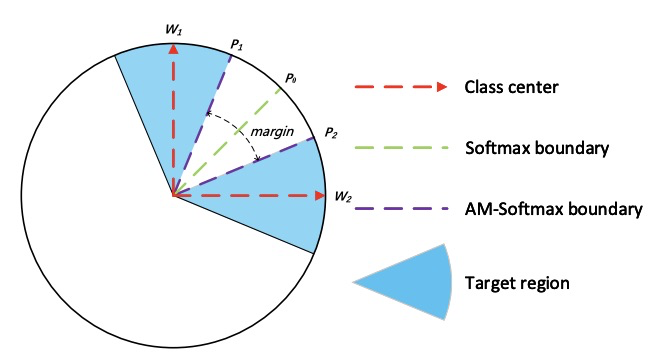
参考链接
https://blog.csdn.net/shaoxiaohu1/article/details/79139039
https://blog.csdn.net/qq_33783896/article/details/80593035
https://blog.csdn.net/shaoxiaohu1/article/details/79139039
https://zhuanlan.zhihu.com/p/64427565
https://blog.csdn.net/wfei101/article/details/82890444?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
https://blog.csdn.net/u013841196/article/details/89920265
https://zhuanlan.zhihu.com/p/137338418
https://zhuanlan.zhihu.com/p/34044634
https://zhuanlan.zhihu.com/p/76541084
https://blog.csdn.net/u013841196/article/details/89888367
总结
目前的$Softmax$主要的一些变形如上,希望给各位带来帮助!欢迎各位补充~
Last updated